Evaluating document chunking for retrieval pipeline
Personal documents accumulate from many sources (bank portals, government sites, email attachments), and they usually arrive with opaque, auto-generated filenames like 3yik1cp8js65.pdf. When a task depends on a specific subset of them, like the forms required to file taxes, locating those documents in the pile becomes a retrieval problem in its own right.
Filename search and Spotlight don’t solve this. They can find a file if you remember its name or a keyword inside it, but a randomly named download gives nothing useful to type, and, more to the point, the question usually isn’t find this file. It’s for this task, which of the required documents do I already have, and which am I missing? Answering that means knowing what each document is and what the task needs. Full-text search can surface what’s present; it can’t tell you what’s absent.
An AI assistant could answer it, but only by reading your personal documents: tax forms, medical records, account statements. That calls for a system that does it without any of that data leaving the machine. FindFiles runs semantic search over a folder of PDFs, subfolders included, and returns a found / missing checklist for a given task, entirely on-device.
The first step of that pipeline is chunking: before anything can be searched, each PDF is split into smaller blocks and embedded. I started with 1,000-character chunks and 200 characters of overlap, the default from a LangChain tutorial. This post is how I evaluated that choice for this specific use case, and the conclusions I drew.
The chunking layer sets the ceiling
Chunking sets the unit of text that gets embedded and retrieved, and every later stage inherits that decision. If the passage that answers a query never lands in a clean chunk, no reranker or scoring step downstream can recover it; those stages can only reorder what retrieval already found. Chunking is the foundation the rest of the pipeline stands on, which is why it’s crucial to validate it before tuning anything above it.
The layers above it, the retrieval method itself and an OCR/extraction problem I ran into while doing this, each turned out to be worth a separate post.
Evaluation setup
I built a labeled evaluation set of 53 real US government forms: W-2, W-4, I-9, the 1099 and 1095 families, several state withholding certificates. For each form I recorded, in a CSV manifest, what the document is and which task-queries it should satisfy. For example, a W-2 is a valid answer to a “starting a new job” query but not to a “renting an apartment” query. The labels are hand-assigned: I went through every form and marked the correct answers per query myself, so the ground truth doesn’t depend on the system’s own classification of the document.
With that in place, I wrote a small harness that re-indexes the whole corpus under a given chunking configuration and measures retrieval directly, holding everything else fixed: the embedding model, the retriever, and the query set. Only the chunking was changed between runs.
I tracked two metrics:
- hit@1: was the correct document ranked first?
- MRR (mean reciprocal rank): if it wasn’t first, how near the top was it?
Then I swept chunk size, overlap, and splitting strategy, each against the 1,000/200 baseline.
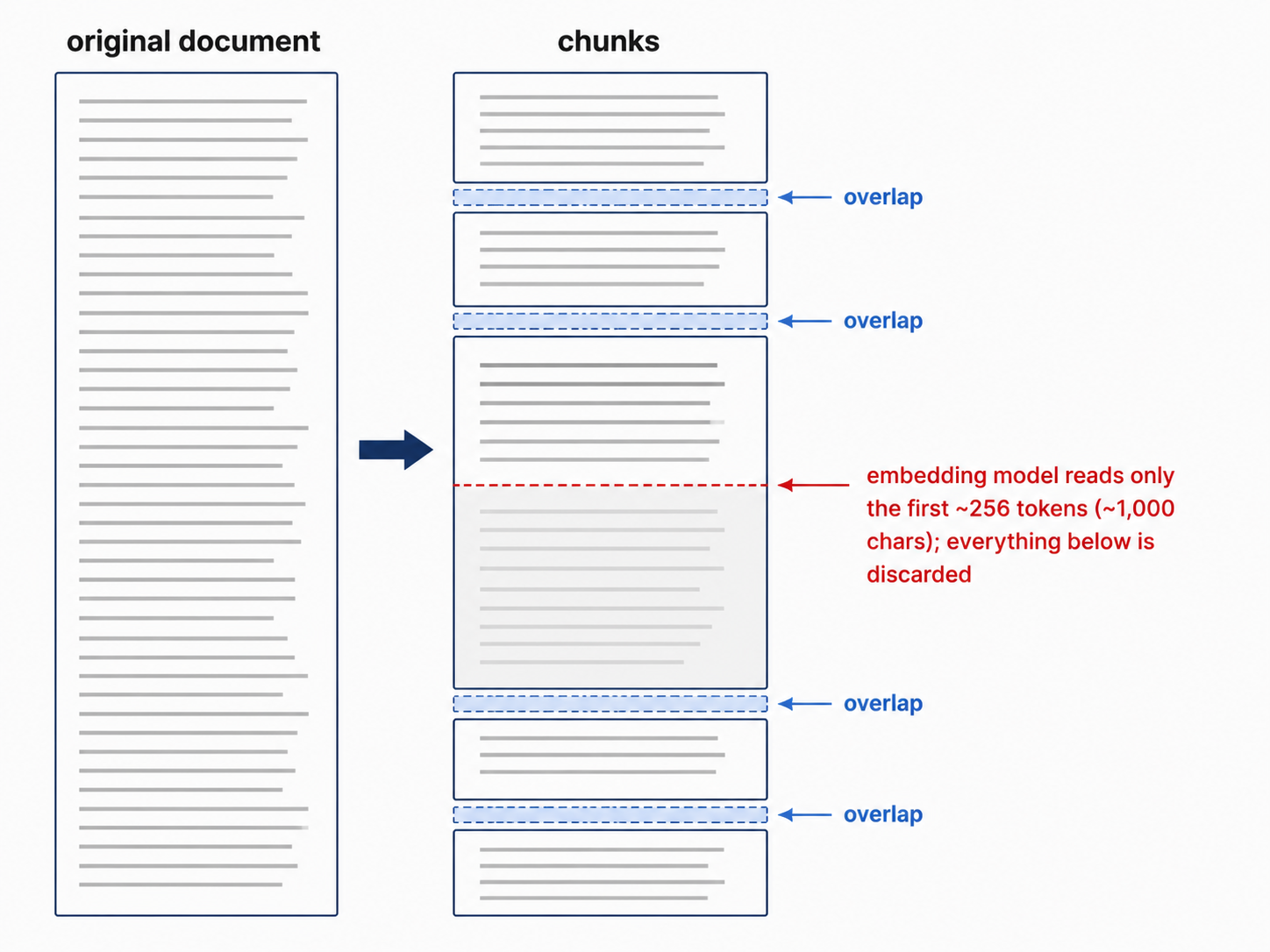
Results
Smaller chunks won. The best configuration, about 512 characters with ~10% overlap, raised hit@1 from 0.73 to 0.83 over the 1,000/200 baseline.
The reason is a property of the embedding model. all-MiniLM-L6-v2, the model FindFiles uses, accepts at most 256 tokens of input (roughly 1,000 characters) and silently truncates anything longer before computing the vector. The baseline’s 1,000-character chunks were sitting right at that limit, and a 1,500-character chunk has its entire second half cut off and never embedded. So past ~1,000 characters, a bigger chunk doesn’t add context; it adds text the model throws away. A smaller chunk fits entirely inside the model’s window, so its vector actually represents all of the text it contains.
Overlap past ~10% hurt. 20% overlap, the baseline, scored below both 0% and 10%, with 10% the best of the three. A little overlap helps when a phrase or field is split across a chunk boundary, so neither side has the complete context. But too much overlap means adjacent chunks are mostly the same text, so one underlying passage shows up as several near-identical chunks. The result list fills with duplicates of the same match, which pushes genuinely different documents down the ranking.
Recursive splitting beat the alternatives. I compared four ways of deciding where one chunk ends and the next begins:
- Recursive: split on the largest natural boundary that fits, paragraphs first, then sentences, then words, so chunks tend to end at clean breaks.
- Fixed-size: cut every N characters regardless of content (I used the same ~512 as the recursive winner, to isolate the effect of where it cuts). Simple, but it splits mid-sentence and mid-word.
- Token-based: the same idea as fixed-size, but counting tokens instead of characters.
- Semantic: embed each sentence and start a new chunk where the topic shifts, a drop in similarity between consecutive sentences.
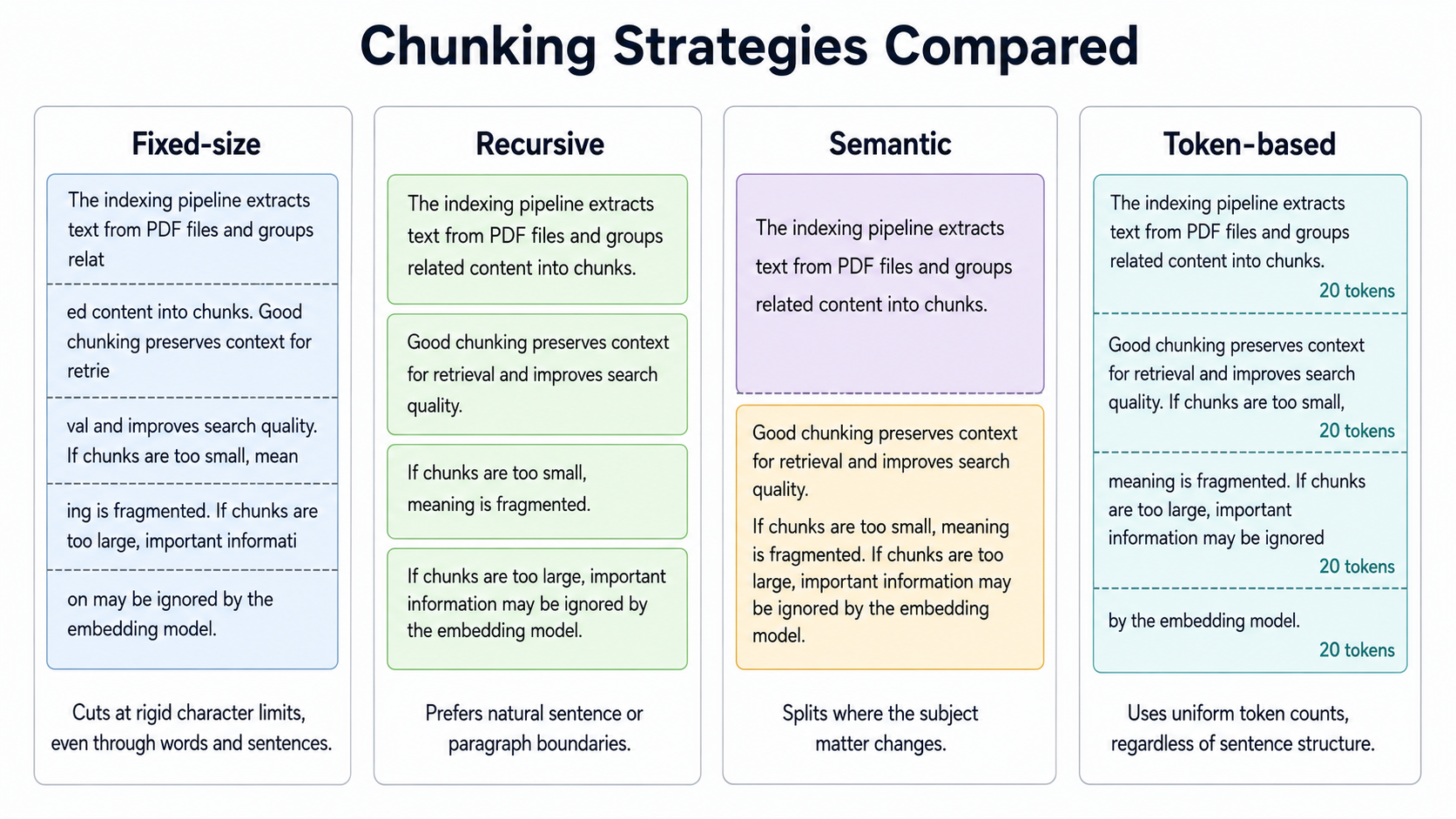
| strategy (dense, hit@1) | score |
|---|---|
| recursive | 0.83 |
| token-based | 0.80 |
| semantic | 0.70 |
| fixed-size | 0.63 |
Recursive came out ahead. Fixed-size was the weakest: cutting blindly every 512 characters routinely splits a field, a date, or a form code across two chunks, so neither chunk carries the complete fact and the embedding of each is muddier. Semantic chunking, the most involved option, was slower (it embeds every sentence at index time), produced larger chunks, and still landed behind plain recursive.
Each method does have a setting where it makes more sense. Fixed-size is reasonable when the text has no structure to respect, like log lines or transcripts. Semantic chunking pays off on long, flowing prose (articles, books, reports) where topic boundaries are real and far apart and keeping a whole idea in one chunk matters. For this use case the documents are neither. They’re short, structured forms whose meaningful boundaries are already the visual ones, a field or a labeled section, which is exactly what recursive splitting targets. The paragraph- and sentence-level breaks it prefers line up closely with the form’s real structure, while semantic boundaries need enough surrounding prose to detect a topic shift and a form doesn’t give the model much to work with. I’d expected the more complex method to win; it didn’t, which is the more useful result. A heavier method has to pay for its cost in the numbers, and on this corpus it didn’t.
Header-heavy PDFs: how text is distributed
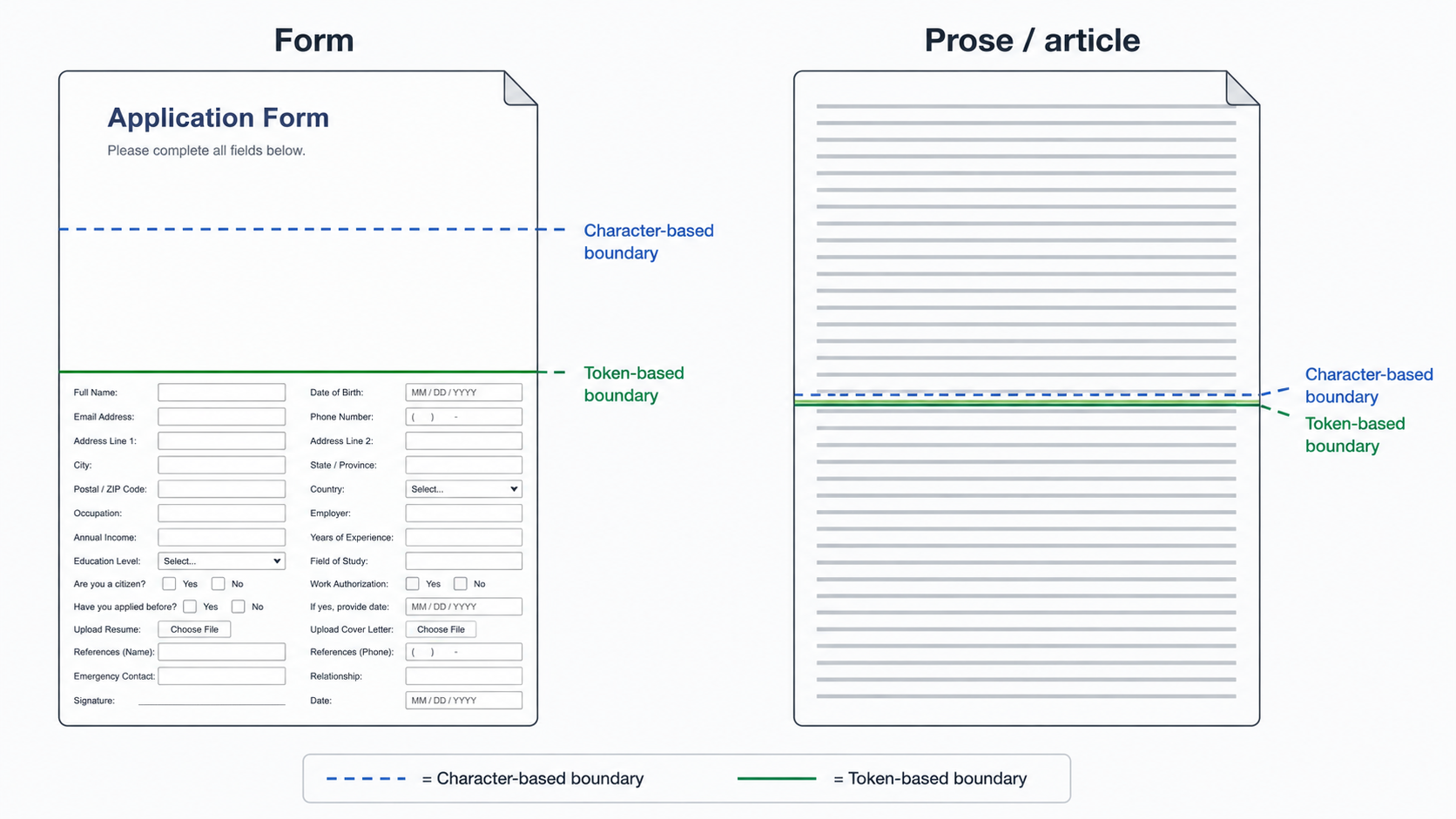
A subtler effect showed up around document shape. These forms aren’t prose. A W-4 opens with a large title and a block of whitespace, then turns dense with fields and instructions further down. The text isn’t spread evenly down the page.
That affects which unit you should split on. If you measure chunks in characters, a chunk taken from the top of a form is mostly whitespace and holds very little real text. Measure in tokens instead, and each chunk carries roughly the same amount of actual content no matter how much blank space surrounds it, since whitespace costs almost no tokens.
So I compared character-based and token-based splitting directly. They came out close to even here. The reason tokens didn’t pull clearly ahead is itself informative: the whitespace-heavy top chunk isn’t dead weight. It contains the form’s title, and for the most common query against this corpus, what is this document, the title is the single most useful thing to match against. Token-counting packs more text into each chunk, but character-counting happens to keep that high-value title chunk intact, so the two roughly cancel out.
The general principle still holds. In prose, text density is roughly uniform, so character and token counting are nearly interchangeable. In structured documents (forms, statements, receipts, anything with a sparse header and a dense body) the unit you count by changes what actually lands in each chunk. If your corpus looks more like forms than essays, it’s worth checking which one you’re using.
Smaller chunks, less overlap
I kept the recursive splitter and moved the chunk size and overlap from 1,000 / 200 to roughly 512 / 10%.
Two caveats on how far that carries. The corpus is small (53 documents) and clean, well-scanned machine-readable government forms, and on the coarser metrics the system is already near its ceiling, which is why I read the result off hit@1 and MRR rather than overall accuracy. Before I treat 512 / 10% as settled, I want a larger, noisier labeled set that looks more like a real personal document folder. This is also one step in a longer evaluation effort: the next is measuring how reliably the local model classifies these documents, where the early answer is not very, which gets its own writeup.
To be exact about what this experiment did and didn’t do: the embedding model, the retriever, the query set, and the labeled answers were all held fixed. The only variable was how each document gets split into chunks. Against that fixed setup, I swept chunk size, overlap, and splitting strategy and scored each on hit@1 and MRR. It matters because chunking is the first transformation in the pipeline and the one every later stage depends on, and the configuration I’d inherited from a tutorial was measurably not the best fit for these documents. A default is an assumption, not a decision.