Semantic File Search with LangChain and Chroma
May 8, 2025
This project enables semantic search over the local file system using OpenAI embeddings, Chroma database and LangChain. It continuously monitors directories, embeds content, and surfaces relevant information in real time when quired.
The design covers key architectural components and their responsibilities, details how new files are automatically processed and indexed, and includes a CLI for real-time search and file discovery. It also lays the groundwork for building document assistants using Retrieval-Augmented Generation (RAG), capable of understanding user intent across multiple documents.
Why Semantic Search for Local Files?
Information retrieval remains a challenge, often due to inconsistent or missing metadata, fragmented storage across local and network drives, and the limitations of traditional keyword-based search.
This system addresses those challenges by converting documents into vector embeddings using OpenAI models and indexing them in Chroma, enabling semantic search that retrieves content based on meaning rather than exact string matches.
System Architecture
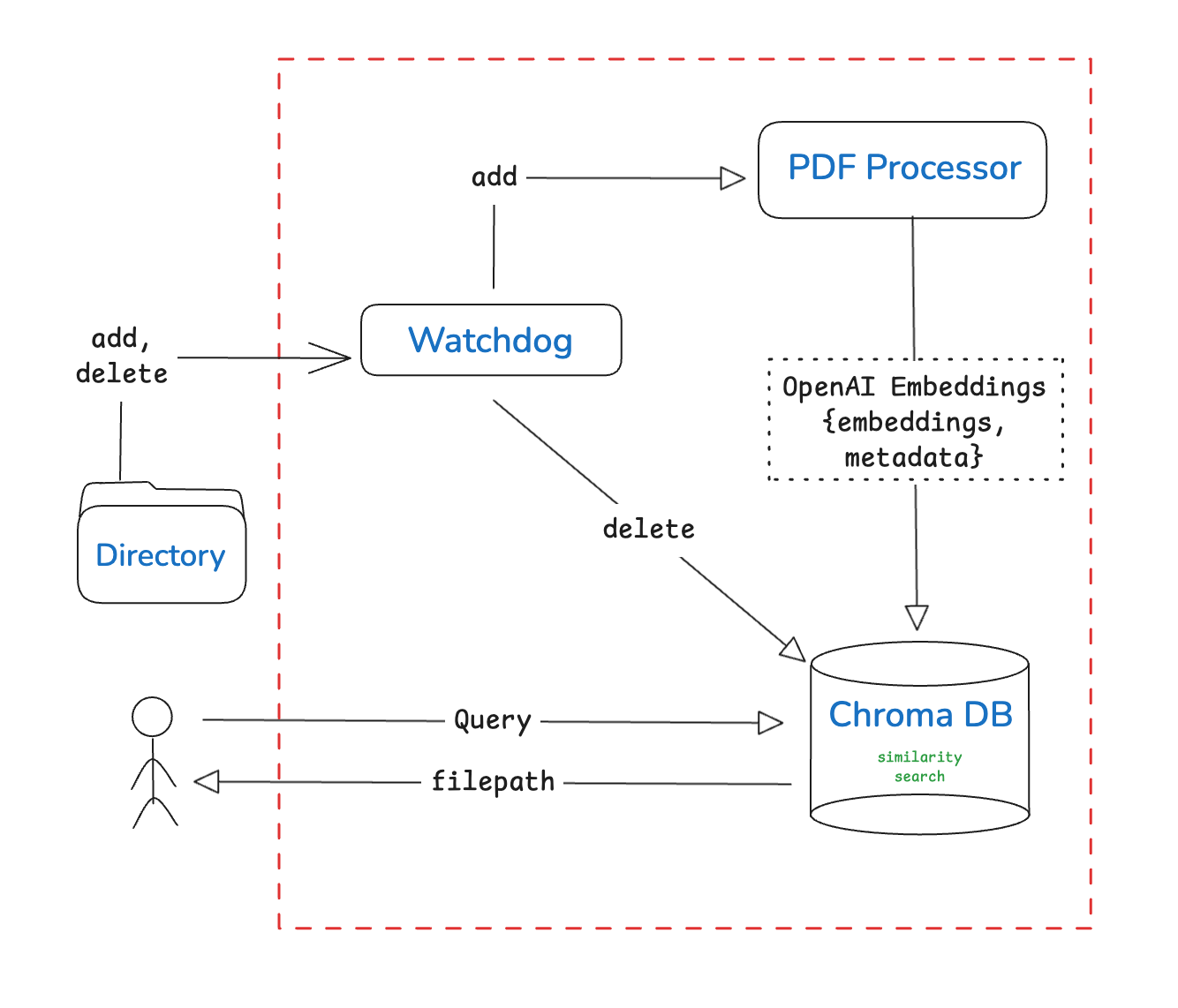
The project is divided into modular components:
Watchdog (File Event Observer)
- Sets up a Watchdog observer to monitor the directory in real time.
- it detects add and delete events.
- On add: it extracts, splits, embeds, and stores the file’s contents in Chroma.
- On delete: it removes the corresponding vector entries from Chroma.
PDF Processor
- Triggered when a new file is added.
- Responsible for loading PDFs using
PyMuPDFLoaderspliting text usingRecursiveCharacterTextSplitter - It converts these chunks into embeddings using OpenAI and passes
{embeddings, metadata}to Chroma for indexing
Vector Store Interface
- Wraps the Chroma vector database and initializes it with OpenAI embeddings
- it handles embedding new files that are added and removes by file path Used by both the PDF Processor and the Watchdog for storage operations.
CLI Interface & System Orchestrator (main.py) in two points
- Initializes the semantic search by validating the target directory, processing and embedding existing PDF files, and launches a Watchdog observer to monitor real-time file system events.
- Provides a command-line interface that accepts user queries, performs vector-based semantic search using Chroma’s similarity search and returns the most relevant file path for discovery.
CLI Interaction Sample
$ python main.py
Enter the folder to monitor: /path/to/folder
Processing existing files in the directory: /path/to/folder
File monitoring started.
What would you like to do?
1. Search for a file
2. Add a file to the monitored folder
> 1
Enter your search query: file to file tax in NY
Matching file found: /path/to/folder/W2_2024.pdf
What’s Next
The current system retrieves the single most relevant document for a given query. The next version will support intent-based search that returns a curated set of related documents.
For example, when a user asks:
“Documents required to file taxes in New York?”
The system will respond with:
- W2
- State 1040
- Receipts
- Deduction summaries
And return their path. Each file will be selected semantically and grouped as part of a complete response.
This includes:
- Building intelligence to extract task-specific insights (e.g., understanding what’s required to file taxes)
- Expanding support for additional file types beyond PDFs
Conclusion
This system enables real-time semantic search over local documents using LangChain, Chroma, and OpenAI embeddings. It automatically indexes new PDFs and supports natural language querying through a command-line interface.
Future iterations will incorporate multi-file reasoning and natural language generation, transforming this utility into a more advanced tool for file discovery and task-specific document retrieval.
GitHub repo here